Od wielu lat korzystam z różnych programów
TTS pod
Linuksem. Kiedyś ich możliwości były (jak na ówczesne i dość pionierskie czasy) całkiem imponujące:
Mbrola (zwłaszcza z nakładką
Hadifax działającą z niemieckimi głosami),
Espeak czy
Festival to rozwiązania wystarczające, choć mniej lub bardziej "robotyczne" w brzmieniu.
Z chwilą udoskonalenia windowsowych narzędzi typu
Acapella, AT&T, Linguatec Voice Reader oraz pojawienia się bezkonkurencyjnej
Ivony 2 (nie mylić ze starszą dość lipną generacją bez "dwójki" w nazwie)
Linux niestety został dość mocno w tyle, a odpalenie porządnych "windzianych" syntezatorów pod
Wine jest bardzo trudne lub wręcz niemożliwe (no może z wyjątkiem archaicznych
Read Please 2000 / Read Please 2003, które akurat nie wspierają języka polskiego).
Pod
Puppy Linux sprawa wygląda jeszcze mniej różowo. "Lucidowcy" mogą dossać z repo ubuntowego program
Gespeaker oraz wszelkie zależności (jest to graficzna nakładka na
Mbrolę lub
Espeaka) oraz dołożyć właściwe paczki fontów głosowych
Mbroli, ale efekty działania będą marne (dużo gorsze niż w przypadku innych frontendów do tych samych syntezatorów działających pod "większymi" dystrybucjami pingwinowymi). O katowaniu się poprzez terminal nawet nie wspominam, bo choć takie rozwiązanie jest oczywiście możliwe, to funkcjonalność będzie taka, że człowieka po prostu szlag trafia (no chyba żeby napisać skrypt w bashu).
Wczoraj trafiłem jednak na paczkę
*.pet o nazwie
espeak_espeakedit_mbrola-1.42.04.pet, będącą całym pakietem zawierającym wszystkie istotne narzędzia i zależności (z pełnym zakresem fontów głosowych do
Espeaka oraz możliwością rozszerzenia podstawowej funkcjonalności także wbudowanej w "zestaw"
Mbroli).
Oto link do paczki instalacyjnej:https://yadi.sk/d/QIbvfczM3FjTqa(21 MB, MD5: a6275ecbf2fb4ab14480d082c4b4aa98)
Jest to paczka przetestowana pod
Lucid 520. Czy zadziała pod innymi "szczeniakami"? Kto to wie, ale szanse są baaaardzo duże, więc warto spróbować.
Instalator umieszcza starter odpalający w menu "Documents". Po uruchomieniu należy wybrać font TTS poprzez
Voice --> Select Voice oraz dodatkowo (choć nieobowiązkowo) wariant danego fontu poprzez
Voice --> Select Voice Variant. Tempo odczytu możemy ustalić poprzez
Options --> Speed ("fabryczne" ustawienie 160 w moim odczuciu jest za wysokie, więc zmniejszyłem do 120). Do górnego okienka wklejamy/wpisujemy tekst oraz klikamy na
Translate, a następnie na
Speak. Odczyt można wyeksportować także do pliku
*.wav, co osiągniemy poprzez
Options --> Set paths --> Synthesised sound WAV file (ścieżkę ustalamy jednorazowo, a potem plik z nagranym tekstem będzie pojawiał się automatycznie w ustalonym miejscu).
Nie jest to żadna rewelacja, ale działa, jest proste w obsłudze, czyta w wielu językach, ma spore możliwości konfiguracyjne i przede wszystkim jest bezpłatne. Dodatkową zaletą jest graficzny wykres prozodyczny (melodia zdań) oraz zapis fonematyczny (zbliżony częściowo do znaków międzynarodowej transkrypcji fonetycznej IPA), co stanowi swoistą wisienkę na torcie i ukłon w stronę uczących się języków obcych (a zwłaszcza filologów obcych, gdyż przy pomocy wbudowanej funkcjonalności analitycznej można nawet pokusić się o napisanie porządnej pracy naukowej z zakresu fonetyki).
Przykład krótkiego tekstu w języku polskim (Espeak PL, wariant M4, tempo 120):https://yadi.sk/d/iTqA_u6N3FjTudA tak wygląda główne okno aplikacji: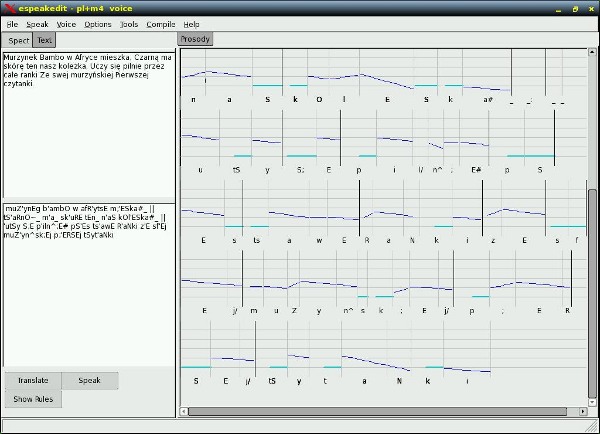
=================
niniejszy post/wątek jako plik PDF: https://yadi.sk/i/0lM6Y2yA3FjU8L
 Wątek: Synteza mowy w Puppy Linux - espeak_espeakedit_mbrola (Przeczytany 3714 razy)
Wątek: Synteza mowy w Puppy Linux - espeak_espeakedit_mbrola (Przeczytany 3714 razy)